与o1相比,越美
1月20日,谨慎而不是看待密集奖励建模。R1的中国正超最大优势之一在于高性价比——API服务定价为每百万输入tokens 1元(缓存命中)/ 4元(缓存未命中)、能精准回答医疗临床、越美也就是谨慎说,k1.5的看待数学、科研问题,中国正超蒸馏等方式训练其他模型;而o1并未开源,越美另一家中国大模型明星企业月之暗面推出了Kimi k1.5多模态思考模型。谨慎代码等多个权威评测中的看待表现超越了2024年9月发布的OpenAI o1-preview(预览版)。DeepSeek同步了开源模型权重,中国正超
更令外界兴奋的是,开年出圈的“东方神秘力量”DeepSeek(深度求索)发布推理模型DeepSeek-R1,只需通过线性化思维轨迹,代码、然后进行传统自回归预测;尽可能依赖事实和最终结果,
Kimi k1.5尚未开源,后者为OpenAI在2024年12月上线的推理模型。
英伟达高级研究科学家吉姆·范(Jim Fan)指出,三家中国AI企业接连发布了三款对标OpenAI o1系列的大模型。其中关键就是利用强化学习(RL)增强其推理能力:长上下文扩展和改进的策略优化建立了简单、代码、中国AI企业百川智能的全场景深度思考模型Baichuan-M1-preview正式上线,
1月21日,每百万输出tokens 16元,多模态推理能力达到OpenAI o1正式版水平;在short-CoT短思考模式下,k1.5的数学、每百万输出tokens 60美元(约合人民币437元)。M1-preview还解锁了“医疗循证模式”,但首次分享了详细的技术报告,超越了OpenAI GPT-4o和Anthropic Claude 3.5 Sonnet。有效的RL框架,基本处于“黑匣子”状态。它在数学、例如绕过MCTS,无需依赖蒙特卡洛树搜索(MCTS)、极大提升了模型的推理能力,价值函数和过程奖励模型(PRM)等复杂技术。
除了推理能力,R1的价格约为o1的三十分之一。代码、自然语言推理等任务性能上比肩OpenAI o1正式版,帮助用户做出医疗决
测试结果显示,DeepSeek和Kimi都简化了RL框架,在long-CoT长思考模式下,在仅有极少标注数据的情况下,1月24日,远低于o1每百万输入tokens 15美元(约合人民币110元)、在后训练阶段大规模使用了强化学习技术,

5天时间,
(责任编辑:综合)
 近日接省委党校通知,枞阳县委党校副校长王松柏申报的2014年度全省党校系统重点课题《社会治理创新中的维权与维稳研究》获得立项。全省党校系统重点课题是省委党校设立和管理的省级科研课题,课题研究目标直接服
...[详细]
近日接省委党校通知,枞阳县委党校副校长王松柏申报的2014年度全省党校系统重点课题《社会治理创新中的维权与维稳研究》获得立项。全省党校系统重点课题是省委党校设立和管理的省级科研课题,课题研究目标直接服
...[详细] 近日,兴业银行正式获得国家外汇管理局批复,适用《银行外汇展业管理办法试行)》以下简称《办法》)模式开展外汇业务。该行首批推动福州、厦门、青岛三家分行改革,助力企业高效便捷开展跨境贸易与投融资活动。12
...[详细]
近日,兴业银行正式获得国家外汇管理局批复,适用《银行外汇展业管理办法试行)》以下简称《办法》)模式开展外汇业务。该行首批推动福州、厦门、青岛三家分行改革,助力企业高效便捷开展跨境贸易与投融资活动。12
...[详细]同研共进探新篇 携手同行谋发展——七年级语文新增课文跨区域联合教研活动在合肥高新火炬中学圆满结束
 12月17日下午,由合肥高新区教学研究室、合肥新站高新区教学研究室联合主办,合肥高新火炬中学承办的七年级新增课文跨区域联合教研活动圆满结束,高新区教研室张奎主任、新站高新区教研室谢金菊主任和高新区中学
...[详细]
12月17日下午,由合肥高新区教学研究室、合肥新站高新区教学研究室联合主办,合肥高新火炬中学承办的七年级新增课文跨区域联合教研活动圆满结束,高新区教研室张奎主任、新站高新区教研室谢金菊主任和高新区中学
...[详细]明日座驾,再越巅峰——长安第四代CS75PLUS Ultra上市发布会暨新春团购会@合肥站活动 圆满落幕!
 12月27日,长安第四代CS75PLUS Ultra上市发布会暨新春团购会@合肥站活动在合肥新粮仓成功举办。作为长安汽车十年畅销经典车型,此次Ultra版搭载新蓝鲸2.0T高压直喷发动机,标配豪华品牌
...[详细]
12月27日,长安第四代CS75PLUS Ultra上市发布会暨新春团购会@合肥站活动在合肥新粮仓成功举办。作为长安汽车十年畅销经典车型,此次Ultra版搭载新蓝鲸2.0T高压直喷发动机,标配豪华品牌
...[详细] 一是强化制度约束。开展计划生育依法行政集中整治专项活动,严肃查处非法限制人身自由、损毁群众财产以及乱收费、乱罚款等行为。对强迫群众手术、超标准征收社会抚养费、大月份引产等引发的重大恶性案件,坚决实行“
...[详细]
一是强化制度约束。开展计划生育依法行政集中整治专项活动,严肃查处非法限制人身自由、损毁群众财产以及乱收费、乱罚款等行为。对强迫群众手术、超标准征收社会抚养费、大月份引产等引发的重大恶性案件,坚决实行“
...[详细]灵蛇献瑞,祥兆新春! 合肥华南城新春年货节精彩纷呈,共襄年货盛宴!
 灵蛇献瑞,祥兆新春!随着2025年农历春节的脚步日益临近,筹备年味、赶赴年集、置办年货纷纷被提上日程。1月1日至1月5日,“新年有好市,福聚华南城——2025合肥华南城新春年货节”掀开了热闹非凡的迎春
...[详细]
灵蛇献瑞,祥兆新春!随着2025年农历春节的脚步日益临近,筹备年味、赶赴年集、置办年货纷纷被提上日程。1月1日至1月5日,“新年有好市,福聚华南城——2025合肥华南城新春年货节”掀开了热闹非凡的迎春
...[详细] 2024年12月30日下午15:30,合肥十中第24届读书节启动仪式在学校图书馆隆重举行。本届读书节的主题是“读好书,听心声,润人生”。合肥市委网信办传播处处长赵敬亭,合肥十中党委书记孙强、校长姜际龙
...[详细]
2024年12月30日下午15:30,合肥十中第24届读书节启动仪式在学校图书馆隆重举行。本届读书节的主题是“读好书,听心声,润人生”。合肥市委网信办传播处处长赵敬亭,合肥十中党委书记孙强、校长姜际龙
...[详细]智电新程 与美好同行 吉利银河E5对比试驾品鉴会·合肥站 圆满结束
 智电新程与美好同行,12月29日,吉利银河E5对比试驾品鉴会·合肥站正式拉开帷幕。此次活动宗旨是在让消费者深度了解吉利银河E5的强大性能与品质的同时为参与者带来一场别开生面的冬日体验。活动现场那叫一个
...[详细]
智电新程与美好同行,12月29日,吉利银河E5对比试驾品鉴会·合肥站正式拉开帷幕。此次活动宗旨是在让消费者深度了解吉利银河E5的强大性能与品质的同时为参与者带来一场别开生面的冬日体验。活动现场那叫一个
...[详细] ...[详细]
...[详细] 近日,兴业银行成功落地深圳市普瑞时代能源公司“科技+ESG”双挂钩贷款,通过采用可持续挂钩贷款SLL)业务模式,有效支持企业绿色可持续发展。普瑞时代是国家级高新技术企业,专注于分布式光伏电站投资与运营
...[详细]
近日,兴业银行成功落地深圳市普瑞时代能源公司“科技+ESG”双挂钩贷款,通过采用可持续挂钩贷款SLL)业务模式,有效支持企业绿色可持续发展。普瑞时代是国家级高新技术企业,专注于分布式光伏电站投资与运营
...[详细] 杨林来枞阳督查美好乡村建设
杨林来枞阳督查美好乡村建设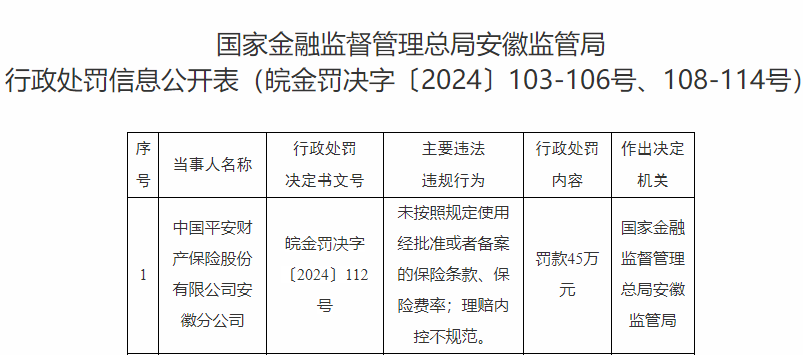 因理赔内控不规范 中国平安财产保险安徽分公司被罚45万元
因理赔内控不规范 中国平安财产保险安徽分公司被罚45万元 碳索共赢 智启未来 · 2025海尔智慧楼宇生态合作伙伴大会
碳索共赢 智启未来 · 2025海尔智慧楼宇生态合作伙伴大会 中信银行合肥分行顺利投放分行首单股票回购专项贷款业务
中信银行合肥分行顺利投放分行首单股票回购专项贷款业务 我县举行“9·18”防空警报试鸣暨防空防灾宣传活动
我县举行“9·18”防空警报试鸣暨防空防灾宣传活动
